
Java解析文件乱码问题
- 2022-04-29 10:30:34
- 2479次 动力节点

动力节点小编来给大家讲一下Java解析文件乱码问题。
1.普通文件中文乱码
普通的文件是指我们平时用记事本可以看到内容的文件,例如.txt结尾的文件,这里为了测试,小编准备了了两个编码的文件,test.txt和test2.txt,test.txt是通过window创建的文件编码是 GBK,test2.txt是在编辑器里创建的,编辑器的编码是 UTF-8;
文件内容如下:
test.txt

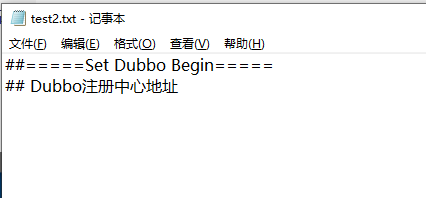
test2.txt
方式一 :字节流读取字节转化为字符串显示
//通过FileInputStream读取字节
String path1 = "C:\Users\yanzhichao\Desktop\test.txt";
String path2 = "C:\Users\yanzhichao\Desktop\test2.txt";
InputStream inputStream1 = null;
InputStream inputStream2 = null;
try{
inputStream1 = new FileInputStream(path1);
byte[] bytes1 = T.IOUtils.toByteArray(inputStream1);
System.out.println("****************************读取test1.txt文件 start *****************************");
System.out.println("使用默认编码-----------------------------");
System.out.println(new String(bytes1));
System.out.println("使用UTF-8编码-----------------------------");
System.out.println(new String(bytes1,"UTF-8"));
System.out.println("使用GBK编码-----------------------------");
System.out.println(new String(bytes1,"GBK"));
System.out.println("使用GB2312编码-----------------------------");
System.out.println(new String(bytes1,"GB2312"));
System.out.println("使用ISO-8859-1编码-----------------------------");
System.out.println(new String(bytes1,"ISO-8859-1"));
System.out.println("****************************读取test1.txt文件 end *****************************");
inputStream2 = new FileInputStream(path2);
byte[] bytes2 = T.IOUtils.toByteArray(inputStream2);
System.out.println("****************************读取test2.txt文件 start *****************************");
System.out.println("使用默认编码-----------------------------");
System.out.println(new String(bytes2));
System.out.println("使用UTF-8编码-----------------------------");
System.out.println(new String(bytes2,"UTF-8"));
System.out.println("使用GBK编码-----------------------------");
System.out.println(new String(bytes2,"GBK"));
System.out.println("使用GB2312编码-----------------------------");
System.out.println(new String(bytes2,"GB2312"));
System.out.println("使用ISO-8859-1编码-----------------------------");
System.out.println(new String(bytes2,"ISO-8859-1"));
System.out.println("****************************读取test2.txt文件 end *****************************");
} catch (Exception e) {
e.printStackTrace();
} finally {
if(inputStream1 != null) {
try {
inputStream1.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
代码中T.IOUtils.toByteArray是封装的工具类,其实里面使用的就是apache的IOUtils,这里不进行累述。
代码读取了两个文件,执行结果如下:
****************************读取test1.txt文件 start *****************************
使用默认编码-----------------------------
111����
使用UTF-8编码-----------------------------
111����
使用GBK编码-----------------------------
111测试
使用GB2312编码-----------------------------
111测试
使用ISO-8859-1编码-----------------------------
111²âÊÔ
****************************读取test1.txt文件 end *****************************
****************************读取test2.txt文件 start *****************************
使用默认编码-----------------------------
##=====Set Dubbo Begin=====
## Dubbo注册中心地址
使用UTF-8编码-----------------------------
##=====Set Dubbo Begin=====
## Dubbo注册中心地址
使用GBK编码-----------------------------
锘�##=====Set Dubbo Begin=====
## Dubbo娉ㄥ唽涓績鍦板潃
使用GB2312编码-----------------------------
锘�##=====Set Dubbo Begin=====
## Dubbo娉ㄥ��涓�蹇��板��
使用ISO-8859-1编码-----------------------------
##=====Set Dubbo Begin=====
## Dubbo注册ä¸å¿ƒåœ°å€
****************************读取test2.txt文件 end *****************************
结果显而易见,编码不同出现中文乱码,这里乱码的原因是因为 new String()。java在字节转化为字符时不指定编码则会使用默认编码,我的编辑器默认编码是 UTF-8,所以出现上面的结果。
方式二 : 字符流读取字符显示
//通过InputStreamReader读取字符
String path1 = "C:\Users\yanzhichao\Desktop\test.txt";
String path2 = "C:\Users\yanzhichao\Desktop\test2.txt";
InputStreamReader reader1 = null;
InputStreamReader reader2 = null;
try{
System.out.println("以字符为单位读取文件内容,一次读多个字节:");
// 一次读多个字符
char[] tempchars = new char[30];
int charread = 0;
reader1 = new InputStreamReader(new FileInputStream(path1));
System.out.println("使用默认编码(UTF-8):");
// 读入多个字符到字符数组中,charread为一次读取字符数
while ((charread = reader1.read(tempchars)) != -1) {
// 同样屏蔽掉
不显示
if ((charread == tempchars.length)
&& (tempchars[tempchars.length - 1] != '
')) {
System.out.print(tempchars);
} else {
for (int i = 0; i < charread; i++) {
if (tempchars[i] == '
') {
continue;
} else {
System.out.print(tempchars[i]);
}
}
}
}
System.out.println();
reader2 = new InputStreamReader(new FileInputStream(path1),"GBK");
System.out.println("使用GBK编码:");
tempchars = new char[30];
charread = 0;
// 读入多个字符到字符数组中,charread为一次读取字符数
while ((charread = reader2.read(tempchars)) != -1) {
// 同样屏蔽掉
不显示
if ((charread == tempchars.length)
&& (tempchars[tempchars.length - 1] != '
')) {
System.out.print(tempchars);
} else {
for (int i = 0; i < charread; i++) {
if (tempchars[i] == '
') {
continue;
} else {
System.out.print(tempchars[i]);
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if(reader1 != null) {
try {
reader1.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(reader2 != null) {
try {
reader2.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
代码只读取了test.txt,执行结果如下:
以字符为单位读取文件内容,一次读多个字节:
使用默认编码(UTF-8):
111����
使用GBK编码:
111测试
显然,和上面是一样的,需要对应编码
2.字节文件损坏、乱码
字节文件一般来说是要对应的工具才能打开的,用记事本打开也看不到什么信息。
这里小编将之前的两个文件加入到压缩文件Desktop.rar中,代码如下:
String path1 = "C:\Users\yanzhichao\Desktop\test.txt";
String path2 = "C:\Users\yanzhichao\Desktop\test2.txt";
String zipName = "C:\Users\yanzhichao\Desktop\Desktop.rar";
String zipName2 = "C:\Users\yanzhichao\Desktop\Desktop2.rar";
String folderName = "test";
List<String> filePathList = new ArrayList<>();
filePathList.add(path1);
filePathList.add(path2);
InputStream is = null;
InputStream is2 = null;
ZipFile zip = null;
ZipFile zip2 = null;
try {
//方法一
zip = new ZipFile(zipName);
ZipParameters para = null;
File file = null;
for (String fliePath : filePathList) {
file = new File(fliePath);
para = new ZipParameters();
para.setCompressionMethod(Zip4jConstants.COMP_DEFLATE);
para.setFileNameInZip(folderName+ fliePath.substring(fliePath.lastIndexOf(File.separator)));
para.setSourceExternalStream(true);
is = new ByteArrayInputStream(T.FileUtils.readFileToByteArray(file));
zip.addStream(is, para);
}
//方法二
zip2 = new ZipFile(zipName2);
ZipParameters para2 = null;
for (String fliePath : filePathList) {
String content = new String(T.IOUtils.toByteArray(new FileInputStream(fliePath)));
para2 = new ZipParameters();
para2.setCompressionMethod(Zip4jConstants.COMP_DEFLATE);
para2.setFileNameInZip(folderName+ fliePath.substring(fliePath.lastIndexOf(File.separator)));
para2.setSourceExternalStream(true);
is2 = new ByteArrayInputStream(content.getBytes());
zip2.addStream(is2, para2);
}
} catch (ZipException | IOException e) {
e.printStackTrace();
} finally {
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (is2 != null) {
try {
is2.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
代码中使用了zip4j工具类进行压缩,读取文件转换为字节数组使用的是apache的工具类。
执行后的结果是Desktop2.rar中的中文存在乱码,其他的正常。
如果对压缩文件进行再压缩时,第二种方法出来的压缩文件不会有问题,但是打开里面的压缩文件会提示损坏。
选你想看










你适合学Java吗?4大专业测评方法
代码逻辑 吸收能力 技术学习能力 综合素质
先测评确定适合在学习
在线申请免费测试名额
价值1998元实验班免费学
价值1998元实验班免费学
 在线咨询
在线咨询
 免费试学
免费试学